Exceptions#

Anything that can go wrong, will go wrong.
— Murphy’s Law #1
Folien/PDF#
Fehler mit Exceptions behandeln#
Exceptions unterbrechen den normalen Verlauf eines Programmes in einem Fehlerfall. Sie dienen dazu den Fehler im Programm zu kommunizieren (sie haben meist eine Fehlermeldung) und werden genutzt, um im Fehlerfall unkontrolliertes Abstürzen des Programmes zu verhindern.
Bekannte Exceptions sollten immer abgefangen. In Python werden sie durch den try-except-Block abgefangen. Dieser startet mit einem try und endet mit einem except. Nach dem try folgt der Block mit der bekannten (oder unbekannten) Exception. Nach dem except folgt der Block zur Fehlerbehandlung.
Es ist zu beachten, dass bei Exceptions keine Wertzuweisung stattfindet (der Wert ist ja nicht bekannt). Betrachten wir mal wieder, die aus der Verzweigung bekannte Division durch 0 mit ihren verschiedenen Fehlerfällen der Null-Division und falscher Datentypen der Eingaben. Ohne diese Fehlerfälle genau zu spezifizieren können wir schreiben.
zaehler = 10
nenner = 0
try:
# Block mit bekannter Exception
ergebnis = zaehler / nenner
# Dieser Teil wird nur ausgeführt wenn keine Exception auftrat
print("Die Division war erfolgreich")
except:
# Fehlerbehandlung
print("Divisionsfehler")
ergebnis = None
print(f"Das Ergebnis von {zaehler}/{nenner} = {ergebnis}")
Divisionsfehler
Das Ergebnis von 10/0 = None
Das except is in dem obigen Fall untypisiert. Damit lassen sich alle Fehler, die auftreten können abfangen (auch unbekannte). Damit fängt der try-except-Block auch Fehler eines falschen Datentyps ab.
zaehler = 'keine_zahl'
nenner = 2
ergebnis = None
try:
ergebnis = zaehler / nenner
except:
print("Divisionsfehler")
print(f"Das Ergebnis von {zaehler}/{nenner} = {ergebnis}")
Divisionsfehler
Das Ergebnis von keine_zahl/2 = None
Das Problem hierbei ist, dass wir keine Information über die Exception erhalten. Deshalb ist es immer sinnvoll die genaue Exception abzufangen und die Fehlermeldung auszugeben. Der allgemeinste Fehlertyp in Python ist die Exception welche wir wie folgt als Variable e abfangen.
zaehler = 10
nenner = 0
ergebnis = None
try:
ergebnis = zaehler / nenner
except Exception as e:
print(f"Divisionsfehler mit Fehler vom typ `{type(e)}` und Meldung `{e}`")
print(f"Das Ergebnis von {zaehler}/{nenner} = {ergebnis}")
Divisionsfehler mit Fehler vom typ `<class 'ZeroDivisionError'>` und Meldung `division by zero`
Das Ergebnis von 10/0 = None
Sind die Exceptions bekannt sollten sie auch typisiert behandelt werden, um spezifische Meldungen auszugeben.
zaehler = 'keine_zahl'
nenner = 0
ergebnis = None
try:
ergebnis = zaehler / nenner
except TypeError as e:
print(f"Zaehler oder Nenner nicht vom Datentyp `int`")
except ZeroDivisionError as e:
print("Teilung durch 0")
print(f"Das Ergebnis von {zaehler}/{nenner} = {ergebnis}")
Zaehler oder Nenner nicht vom Datentyp `int`
Das Ergebnis von keine_zahl/0 = None
Der try-except-Block unterstütz auch die else-Anweisung, welche immer ausgeführt wird, wenn keine Exception auftritt. Ferner gibt es die finally-Anweisung, welche immer ausgeführt wird also im fehlerfreien Fall und im Fehlerfall.
Soll zum Beispiel eine Ausgabe nur gemacht werden, wenn der try-Block erfolgreich war, nutzen wir else.
zaehler = 2
nenner = 1
ergebnis = None
#if no_error_then_execute_full:
try:
ergebnis = zaehler / nenner
#elif error of type TypeError:
except TypeError as e:
print(f"Zaehler oder Nenner nicht vom Datentyp `int`")
except ZeroDivisionError as e:
print("Teilung durch 0")
else:
print(f"Die Division war erfolgreich und resultiert in {zaehler}/{nenner} = {ergebnis}")
Die Division war erfolgreich und resultiert in 2/1 = 2.0
Soll immer eine Ausgabe erfolgen können wir finally verwenden. Dies wird häufig verwendet, um Schritte durchzuführen die auch im Fehlerfall gemacht werden sollen, z.B. um Verbindungen zu Dateien oder zu einer Datenbank zu schließen, damit diese nicht unendlich lange offen bleiben (und irgendwann zu Fehlern führen).
zaehler = 'keine_zahl'
nenner = 0
ergebnis = None
try:
ergebnis = zaehler / nenner
except TypeError as e:
print(f"Zaehler oder Nenner nicht vom Datentyp `int`")
except ZeroDivisionError as e:
print("Teilung durch 0")
finally:
print(f"Das Ergebnis von {zaehler}/{nenner} = {ergebnis}")
Zaehler oder Nenner nicht vom Datentyp `int`
Das Ergebnis von keine_zahl/0 = None
Exceptions selbst erzeugen#
Exceptions können auch selbst mit raise erzeugt werden. Das ist sinnvoll, wenn in dem eigenen Code Fehler auftreten können, die woanders behandelt werden müssen. Hierbei muss ein Fehlertyp angegeben werden. Entweder man nutzt den allgemeinsten Fehlertyp Exception, einen passenden Standardfehler von Python oder einen selbst definierten. Es ist ratsam meist spezifische Fehlertypen zu nutzen, da der Typ des Fehlers viel beim Behandeln und Debuggen hilft.
Definieren wir als Beispiel unsere eigene Divisionsfunktion mit klarer Fehlerbenenung ob Zähler oder Nenner vom falschen Typ sind. Hier wollen wir, dass anstatt des TypeError ein ValueError erzeugt wird. Bei einer Division durch 0 soll anstatt eines Fehlers der Wert None zurückgegeben werden.
def division(zaehler, nenner):
if not isinstance(nenner, (int, float)):
raise ValueError(f"Nenner nicht vom Datentyp `int` oder `float`")
elif not isinstance(zaehler, (int, float)):
raise ValueError(f"Zaehler nicht vom Datentyp `int` oder `float`")
elif nenner == 0:
print("Warnung Division durch 0")
return None
else:
ergebnis = zaehler / nenner
print(f"Das Ergebnis von {zaehler}/{nenner} = {ergebnis}")
return ergebnis
zaehler = "test"
nenner = 0
ergebnis = division(zaehler, nenner)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[8], line 4
1 zaehler = "test"
2 nenner = 0
----> 4 ergebnis = division(zaehler, nenner)
Cell In[7], line 5, in division(zaehler, nenner)
3 raise ValueError(f"Nenner nicht vom Datentyp `int` oder `float`")
4 elif not isinstance(zaehler, (int, float)):
----> 5 raise ValueError(f"Zaehler nicht vom Datentyp `int` oder `float`")
6 elif nenner == 0:
7 print("Warnung Division durch 0")
ValueError: Zaehler nicht vom Datentyp `int` oder `float`
zaehler= 10
nenner = 2
ergebnis = division(zaehler, nenner)
Das Ergebnis von 10/2 = 5.0
zaehler = 10
nenner = 1
ergebnis = division(zaehler, nenner)
Das Ergebnis von 10/1 = 10.0
Fehlerbehandlung bei Funktionen im Stack#
Exceptions werden im Stack (Aufrufreihenfolge der Funktionen) nach oben weitergegeben, bis sie entweder abgefangen und behandelt werden oder das Programm abstürzt, wenn das Ende des Stacks erreicht wird. Ziel des Abfangens und Behandelns von Exceptions ist es das Programm zurück in einen Zustand zu bringen in dem es weiterlaufen kann.
Als Beispiel wollen wir eine rekursive Funktion definieren, welche uns einen Fehler ausgibt, wenn die Rekurssionstiefe zu groß wird um einen Stack-Overflow-Fehler zu vermeiden. Wir nutzen als Beispiel die Fakultät aus dem Rekursionbeispiel.
def factorial_recursiv(x, depth=1):
if depth > 20:
raise RecursionError("Recursion zu tief")
if x > 1:
return x * factorial_recursiv(x-1, depth+1)
else:
return 1
factorial_recursiv(20)
2432902008176640000
factorial_recursiv(21)
---------------------------------------------------------------------------
RecursionError Traceback (most recent call last)
Cell In[13], line 1
----> 1 factorial_recursiv(21)
Cell In[11], line 5, in factorial_recursiv(x, depth)
3 raise RecursionError("Recursion zu tief")
4 if x > 1:
----> 5 return x * factorial_recursiv(x-1, depth+1)
6 else:
7 return 1
Cell In[11], line 5, in factorial_recursiv(x, depth)
3 raise RecursionError("Recursion zu tief")
4 if x > 1:
----> 5 return x * factorial_recursiv(x-1, depth+1)
6 else:
7 return 1
[... skipping similar frames: factorial_recursiv at line 5 (17 times)]
Cell In[11], line 5, in factorial_recursiv(x, depth)
3 raise RecursionError("Recursion zu tief")
4 if x > 1:
----> 5 return x * factorial_recursiv(x-1, depth+1)
6 else:
7 return 1
Cell In[11], line 3, in factorial_recursiv(x, depth)
1 def factorial_recursiv(x, depth=1):
2 if depth > 20:
----> 3 raise RecursionError("Recursion zu tief")
4 if x > 1:
5 return x * factorial_recursiv(x-1, depth+1)
RecursionError: Recursion zu tief
In der obigen Fehlermeldung bringt das Programm selbst zum erliegen (es stürtzt allerdings nicht der ganze Kernel ab, wie beim Stack-Overflow-Fehler). Um das zu vermeiden müssen wir den Fehler mit try-except abfangen. In der Fehlermeldung oben deutet sich schon der Stack-Trace an, also die Liste der Funktionsaufrufe die auf dem Stack gesammelt wurde.
import traceback
try:
factorial_recursiv(21)
except RecursionError as e:
print(e)
traceback.print_exc()
Recursion zu tief
Traceback (most recent call last):
File "/var/folders/0c/805v004947lf04d_w7xm50rc0000gn/T/ipykernel_71989/841887965.py", line 3, in <module>
factorial_recursiv(21)
File "/var/folders/0c/805v004947lf04d_w7xm50rc0000gn/T/ipykernel_71989/43912226.py", line 5, in factorial_recursiv
return x * factorial_recursiv(x-1, depth+1)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/var/folders/0c/805v004947lf04d_w7xm50rc0000gn/T/ipykernel_71989/43912226.py", line 5, in factorial_recursiv
return x * factorial_recursiv(x-1, depth+1)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/var/folders/0c/805v004947lf04d_w7xm50rc0000gn/T/ipykernel_71989/43912226.py", line 5, in factorial_recursiv
return x * factorial_recursiv(x-1, depth+1)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[Previous line repeated 17 more times]
File "/var/folders/0c/805v004947lf04d_w7xm50rc0000gn/T/ipykernel_71989/43912226.py", line 3, in factorial_recursiv
raise RecursionError("Recursion zu tief")
RecursionError: Recursion zu tief
Debugging mit print()#
Logische Fehler treten häufig erst dynamisch auf und lassen sich nicht durch statische Code-Analyse durch Lint-Tools finden. Hier muss man dann den aktuellen Programmfluss nachvollziehen. Dies nennt man Debugging. Die einfachste Form ist das print-Debugging bei der man den Code mit print()-Befehlen zuspammt.
Wir erweitern mal unsere Divisionsfunktion mit schönen vielen print()-Statements. Üblich ist es zum Beispiel, die Eingangsparameter auszugeben, Fehler und Warnungen auszugeben, als auch dann Ergebnisse zu loggen.
def division(zaehler, nenner):
print(f"Debug: Eingabe Zaehler: {zaehler}")
print(f"Debug: Eingabe Nenner: {nenner}")
if not isinstance(nenner, (int, float)):
print(f"Error: Nenner nicht vom Datentyp `int` oder `float`, sondern vom Typ {type(nenner)}")
raise ValueError(f"Nenner nicht vom Datentyp `int` oder `float`, sondern vom Typ {type(nenner)}")
elif not isinstance(zaehler, (int, float)):
print(f"Error: Zaehler nicht vom Datentyp `int` oder `float`, sondern vom Typ {type(zaehler)}")
raise ValueError(f"Zaehler nicht vom Datentyp `int` oder `float`, sondern vom Typ {type(zaehler)}")
elif not nenner:
print("Warning: Division durch 0")
return None
else:
ergebnis = zaehler / nenner
print(f"Info: Das Ergebnis von {zaehler}/{nenner} = {ergebnis}")
return ergebnis
Jetzt können wir insbesondere im Fehlerfall sehr gut nachvollziehen was genau geschehen ist. Zum Beispiel bei der Division durch 0.
division(10, 0)
Debug: Eingabe Zaehler: 10
Debug: Eingabe Nenner: 0
Warning: Division durch 0
Allerdings haben wir auch im korrekten Fall sehr viele Ausgaben. Das kann sehr störend sein, weil man dann richtige Fehler sehr schnell übersieht. Zum Beispiel erzeugen wir zehn Divisionen, von der eine eine Division durch 0 war.
for nenner in range(-2, 8):
division(10, nenner)
Debug: Eingabe Zaehler: 10
Debug: Eingabe Nenner: -2
Info: Das Ergebnis von 10/-2 = -5.0
Debug: Eingabe Zaehler: 10
Debug: Eingabe Nenner: -1
Info: Das Ergebnis von 10/-1 = -10.0
Debug: Eingabe Zaehler: 10
Debug: Eingabe Nenner: 0
Warning: Division durch 0
Debug: Eingabe Zaehler: 10
Debug: Eingabe Nenner: 1
Info: Das Ergebnis von 10/1 = 10.0
Debug: Eingabe Zaehler: 10
Debug: Eingabe Nenner: 2
Info: Das Ergebnis von 10/2 = 5.0
Debug: Eingabe Zaehler: 10
Debug: Eingabe Nenner: 3
Info: Das Ergebnis von 10/3 = 3.3333333333333335
Debug: Eingabe Zaehler: 10
Debug: Eingabe Nenner: 4
Info: Das Ergebnis von 10/4 = 2.5
Debug: Eingabe Zaehler: 10
Debug: Eingabe Nenner: 5
Info: Das Ergebnis von 10/5 = 2.0
Debug: Eingabe Zaehler: 10
Debug: Eingabe Nenner: 6
Info: Das Ergebnis von 10/6 = 1.6666666666666667
Debug: Eingabe Zaehler: 10
Debug: Eingabe Nenner: 7
Info: Das Ergebnis von 10/7 = 1.4285714285714286
Debugging mit logging#
Deshalb verwendet man bei komplexeren Programmen meist ein logging-Paket. Diese erlauben es print-Statements Kategorien zuzuordnen und anhand dieser zu filtern. In der Python-Bibliothek logging sind die Kategorien: debug, info, warning, error und critical.
import logging
log=logging.getLogger("meinlog")
def division(zaehler, nenner):
log.debug(f"Eingabe Zaehler: {zaehler}")
log.debug(f"Eingabe Nenner: {nenner}")
if not isinstance(nenner, (int, float)):
log.error(f"Nenner nicht vom Datentyp `int` oder `float`, sondern vom Typ {type(nenner)}")
raise ValueError(f"Nenner nicht vom Datentyp `int` oder `float`, sondern vom Typ {type(nenner)}")
elif not isinstance(zaehler, (int, float)):
log.error(f"Zaehler nicht vom Datentyp `int` oder `float`, sondern vom Typ {type(zaehler)}")
raise ValueError(f"Zaehler nicht vom Datentyp `int` oder `float`, sondern vom Typ {type(zaehler)}")
elif not nenner:
log.warning("Division durch 0")
return None
else:
ergebnis = zaehler / nenner
log.info(f"Das Ergebnis von {zaehler}/{nenner} = {ergebnis}")
return ergebnis
Wenn wir jetzt die Funktion aufrufen, sehen wir nur noch die Division durch 0 Warnung.
log.setLevel(logging.WARNING)
log.addHandler(sh)
for nenner in range(-2, 8):
division(10, nenner)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[19], line 2
1 log.setLevel(logging.WARNING)
----> 2 log.addHandler(sh)
3 for nenner in range(-2, 8):
4 division(10, nenner)
NameError: name 'sh' is not defined
Wir können allerdings bei Bedarf, wie bei der Fehlersuche den Loglevel auch erhöhen. Zum Beispiel wollen wir alle Debug-Nachrichten erhalten.
log.setLevel(logging.DEBUG)
log.addHandler(sh)
for nenner in range(-2, 8):
division(10, nenner)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[20], line 2
1 log.setLevel(logging.DEBUG)
----> 2 log.addHandler(sh)
3 for nenner in range(-2, 8):
4 division(10, nenner)
NameError: name 'sh' is not defined
Ferner erlaub das Logging auch automatisch weitere Informationen hinzuzufügen. Wir sehen im Log oben bereits, das nicht nur das Level (INFO, DEBUG, WARNING) sondern auch den Namen des Loggers (meinlog). Wir können dieses Format anpassen um z.B. auch die Zeit auszugeben, was insbesondere wichtig ist um zu verstehen wann etwas passiert ist.
sh=logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s %(name)s %(levelname)s: %(message)s')
sh.setFormatter(formatter)
log.addHandler(sh)
log.setLevel(logging.DEBUG)
for nenner in range(-2, 8):
division(10, nenner)
2026-01-22 14:46:50,544 meinlog DEBUG: Eingabe Zaehler: 10
2026-01-22 14:46:50,544 meinlog DEBUG: Eingabe Nenner: -2
2026-01-22 14:46:50,544 meinlog INFO: Das Ergebnis von 10/-2 = -5.0
2026-01-22 14:46:50,544 meinlog DEBUG: Eingabe Zaehler: 10
2026-01-22 14:46:50,544 meinlog DEBUG: Eingabe Nenner: -1
2026-01-22 14:46:50,544 meinlog INFO: Das Ergebnis von 10/-1 = -10.0
2026-01-22 14:46:50,544 meinlog DEBUG: Eingabe Zaehler: 10
2026-01-22 14:46:50,545 meinlog DEBUG: Eingabe Nenner: 0
2026-01-22 14:46:50,545 meinlog WARNING: Division durch 0
2026-01-22 14:46:50,545 meinlog DEBUG: Eingabe Zaehler: 10
2026-01-22 14:46:50,545 meinlog DEBUG: Eingabe Nenner: 1
2026-01-22 14:46:50,545 meinlog INFO: Das Ergebnis von 10/1 = 10.0
2026-01-22 14:46:50,545 meinlog DEBUG: Eingabe Zaehler: 10
2026-01-22 14:46:50,545 meinlog DEBUG: Eingabe Nenner: 2
2026-01-22 14:46:50,545 meinlog INFO: Das Ergebnis von 10/2 = 5.0
2026-01-22 14:46:50,546 meinlog DEBUG: Eingabe Zaehler: 10
2026-01-22 14:46:50,546 meinlog DEBUG: Eingabe Nenner: 3
2026-01-22 14:46:50,546 meinlog INFO: Das Ergebnis von 10/3 = 3.3333333333333335
2026-01-22 14:46:50,546 meinlog DEBUG: Eingabe Zaehler: 10
2026-01-22 14:46:50,546 meinlog DEBUG: Eingabe Nenner: 4
2026-01-22 14:46:50,546 meinlog INFO: Das Ergebnis von 10/4 = 2.5
2026-01-22 14:46:50,546 meinlog DEBUG: Eingabe Zaehler: 10
2026-01-22 14:46:50,546 meinlog DEBUG: Eingabe Nenner: 5
2026-01-22 14:46:50,547 meinlog INFO: Das Ergebnis von 10/5 = 2.0
2026-01-22 14:46:50,547 meinlog DEBUG: Eingabe Zaehler: 10
2026-01-22 14:46:50,547 meinlog DEBUG: Eingabe Nenner: 6
2026-01-22 14:46:50,547 meinlog INFO: Das Ergebnis von 10/6 = 1.6666666666666667
2026-01-22 14:46:50,547 meinlog DEBUG: Eingabe Zaehler: 10
2026-01-22 14:46:50,547 meinlog DEBUG: Eingabe Nenner: 7
2026-01-22 14:46:50,547 meinlog INFO: Das Ergebnis von 10/7 = 1.4285714285714286
In der Praxis wird das Logging sehr häufig insbesondere in Cloud-Anwendungen verwendet. Da diese ja keine Bildschirme haben, müssen Fehler in Logs gesucht werden. Solange alles ok ist, läuft so eine Anwendung dann z.B. im Log-Level INFO, mit nur wenig Ausgaben. Tritt ein Fehler auf, so wird der Server auf das Log-Level DEBUG gesetzt und man sucht in den detaillierten Logs dann nach Informationen, um den Fehler einzugrenzen.
Debugging durch Debug-Oberflächen#
Viele integrierte Entwicklungsumgebungen (IDE) bieten an direkt Debugger auszuführen. Diese Debugger erlauben es die dynamische Ausführung des Codes zu unterbrechen. Ziel ist es kurz vor Auftreten des Fehlers die Ausführung anzuhalten, um dann das Fehlerverhalten genau beobachten zu können.
Dabei werden meist zwei Formen der Unterbrechung unterstützt:
Die Unterbrechung in bestimmten Code-Zeilen mit Hilfe von Breakpoints.
Die Unterbrechung bei bestimmten Exceptions.
Debugging in Jupyter-Notebooks in VSCode#
Die Debug-Oberflächen sehen je nach IDE etwas anders aus, verfügen aber über ähnliche Funktionen. Dieses Jupyter Notebook wurde in VSCode geschrieben, welches wir als erstes Beispiel betrachten.
Dafür kann man meist in der IDE links neben eine Zeile klicken um einen Breakpoint ⬤ zu setzen. Wir setzen dafür einen Breakpoint auf die Zeile 11 auf die Ausgabe der Warnung.

Dann wird der Code in einer speziellen Debugumgebung ausgeführt, die es erlaub die Ausführung zu unterbrechen. In unserm Notebook in VSCode starten wird diese durch das Symbol  .
.
def division(zaehler, nenner):
log.debug(f"Eingabe Zaehler: {zaehler}")
log.debug(f"Eingabe Nenner: {nenner}")
if not isinstance(nenner, (int, float)):
log.error(f"Nenner nicht vom Datentyp `int` oder `float`, sondern vom Typ {type(nenner)}")
raise ValueError(f"Nenner nicht vom Datentyp `int` oder `float`, sondern vom Typ {type(nenner)}")
elif not isinstance(zaehler, (int, float)):
log.error(f"Zaehler nicht vom Datentyp `int` oder `float`, sondern vom Typ {type(zaehler)}")
raise ValueError(f"Zaehler nicht vom Datentyp `int` oder `float`, sondern vom Typ {type(zaehler)}")
elif not nenner:
log.warning("Division durch 0")
return None
else:
ergebnis = zaehler / nenner
log.info(f"Das Ergebnis von {zaehler}/{nenner} = {ergebnis}")
return ergebnis
division(10, 0)
2026-01-22 14:46:50,552 meinlog DEBUG: Eingabe Zaehler: 10
2026-01-22 14:46:50,553 meinlog DEBUG: Eingabe Nenner: 0
2026-01-22 14:46:50,553 meinlog WARNING: Division durch 0
Dies startet den Debug-Modus. In diesem wird die aktuelle Zeile vorgehoben als auch die aktuellen Variablen im Speicher angezeigt.
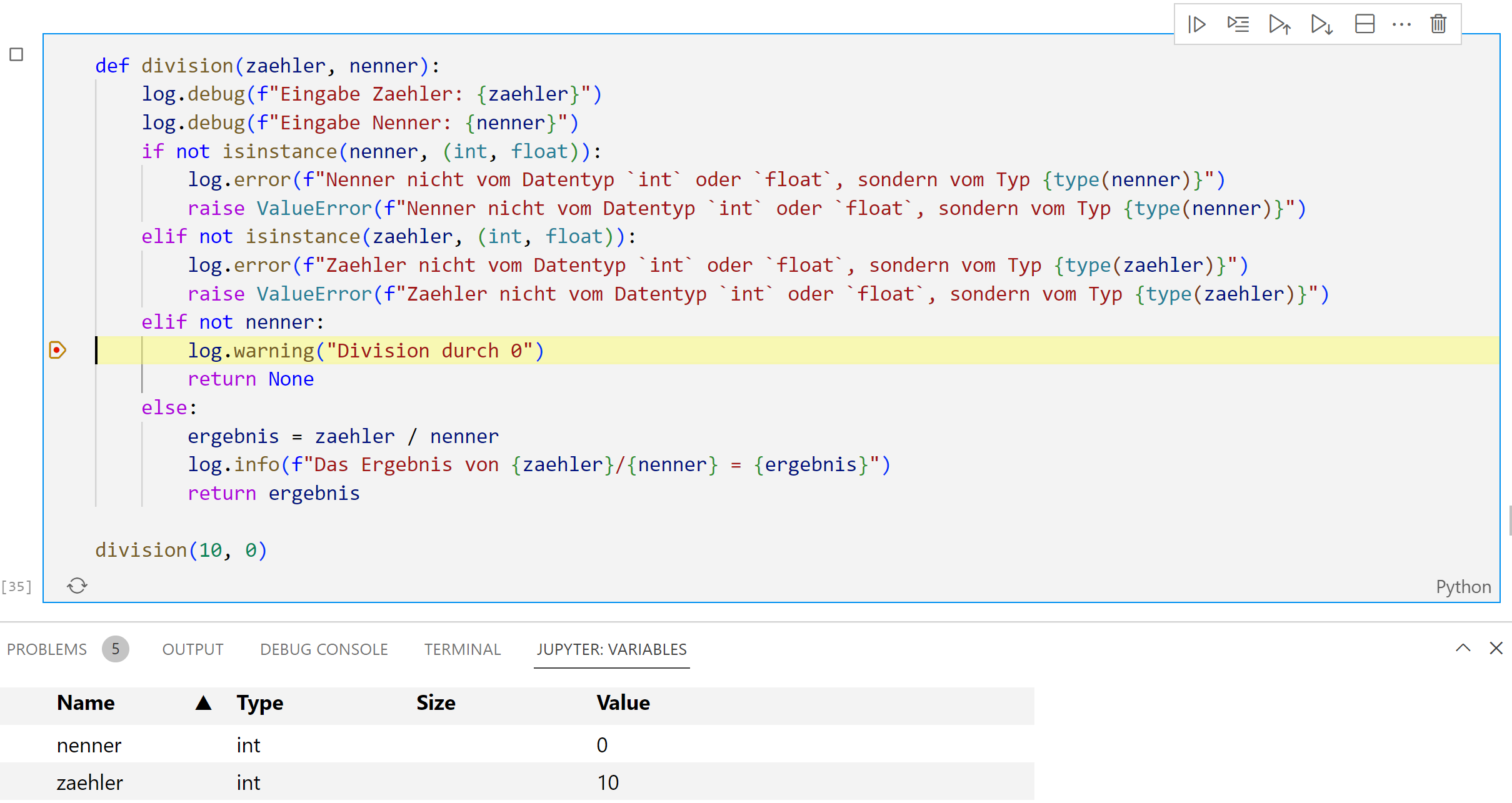
In der Debugumgebung kann man dann Zeile für Zeile vorgehen durch drücken von und damit nachvollziehen wie das Programm bearbeitet wird und welche Variablen sich ändern.