Tabellen mit SQL analysieren#

If you think you understand SQL, you’re probably wrong.
— C. J. Date
Folien/PDF#
Praxisbeispiel#
Informationen sind in der Praxis meist über verschiedene Systeme und Tabellen verteilt und müssen oft zusammengeführt verarbeitet werden, um daraus anwendbares Wissen abzuleiten.
Die Hansestadt Rostock bietet zum Beispiel viele relevante Daten für Bau- und Umweltingenieure auf dem OpenData Portal Rostock.
Dort erhalten wir zum Beispiel:
Wie in den letzten Beispielen gezeigt können wir uns die Daten auch sehr einfach in Python herunter laden und anzeigen. Dafür nutzen wir das CSV Format das auf den Webseiten angeboten wird und die Python Pakete urllib und pandas. Wir öffnen zuerst die Datei im Internet mit urllib.request.urlopen und laden sie dann in Pandas als Tabelle mit pd.read_csv(f). Zuletzt zeigen wir die ersten 5 Zeilen der Tabelle mit .head() an.
import urllib.request
import pandas as pd
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[1], line 2
1 import urllib.request
----> 2 import pandas as pd
ModuleNotFoundError: No module named 'pandas'
# Siehe https://www.opendata-hro.de/dataset/baustellen
with urllib.request.urlopen(f'https://geo.sv.rostock.de/download/opendata/baustellen/baustellen.csv') as f:
baustellen = pd.read_csv(f, usecols=["latitude", "longitude", "strasse_schluessel", "sparte", "von", "nach", "baubeginn", "bauende", "verkehrsbeeintraechtigungen", "baumassnahme"] )#, parse_dates=["baubeginn", "bauende"]
baustellen["baubeginn"] = pd.to_datetime(baustellen["baubeginn"], format="%Y/%m/%d %H:%M:%S%z", errors="coerce", utc=True).dt.strftime("%Y-%m-%d %H:%M:%S")
baustellen["bauende"] = pd.to_datetime(baustellen["bauende"], format="%Y/%m/%d %H:%M:%S%z", errors="coerce", utc=True).dt.strftime("%Y-%m-%d %H:%M:%S")
baustellen.head()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[2], line 3
1 # Siehe https://www.opendata-hro.de/dataset/baustellen
2 with urllib.request.urlopen(f'https://geo.sv.rostock.de/download/opendata/baustellen/baustellen.csv') as f:
----> 3 baustellen = pd.read_csv(f, usecols=["latitude", "longitude", "strasse_schluessel", "sparte", "von", "nach", "baubeginn", "bauende", "verkehrsbeeintraechtigungen", "baumassnahme"] )#, parse_dates=["baubeginn", "bauende"]
4 baustellen["baubeginn"] = pd.to_datetime(baustellen["baubeginn"], format="%Y/%m/%d %H:%M:%S%z", errors="coerce", utc=True).dt.strftime("%Y-%m-%d %H:%M:%S")
5 baustellen["bauende"] = pd.to_datetime(baustellen["bauende"], format="%Y/%m/%d %H:%M:%S%z", errors="coerce", utc=True).dt.strftime("%Y-%m-%d %H:%M:%S")
NameError: name 'pd' is not defined
# Siehe https://geo.sv.rostock.de/download/opendata/adressenliste
with urllib.request.urlopen(f'https://geo.sv.rostock.de/download/opendata/adressenliste/adressenliste.csv') as f:
adressenliste=pd.read_csv(f, usecols=["gemeinde_schluessel", "gemeindeteil_name", "strasse_name", "strasse_schluessel", "hausnummer", "hausnummer_zusatz", "postleitzahl"])
adressenliste.head()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[3], line 3
1 # Siehe https://geo.sv.rostock.de/download/opendata/adressenliste
2 with urllib.request.urlopen(f'https://geo.sv.rostock.de/download/opendata/adressenliste/adressenliste.csv') as f:
----> 3 adressenliste=pd.read_csv(f, usecols=["gemeinde_schluessel", "gemeindeteil_name", "strasse_name", "strasse_schluessel", "hausnummer", "hausnummer_zusatz", "postleitzahl"])
4 adressenliste.head()
NameError: name 'pd' is not defined
# Siehe https://www.opendata-hro.de/dataset/gemeinden_mecklenburg-vorpommern
with urllib.request.urlopen(f'https://geo.sv.rostock.de/download/opendata/gemeinden_mecklenburg-vorpommern/gemeinden_mecklenburg-vorpommern.csv') as f:
gemeinden=pd.read_csv(f, usecols=["kreis_name", "kreis_schluessel", "gemeindeverband_name", "gemeindeverband_schluessel", "gemeinde_name", "gemeinde_schluessel"])
gemeinden.head()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[4], line 3
1 # Siehe https://www.opendata-hro.de/dataset/gemeinden_mecklenburg-vorpommern
2 with urllib.request.urlopen(f'https://geo.sv.rostock.de/download/opendata/gemeinden_mecklenburg-vorpommern/gemeinden_mecklenburg-vorpommern.csv') as f:
----> 3 gemeinden=pd.read_csv(f, usecols=["kreis_name", "kreis_schluessel", "gemeindeverband_name", "gemeindeverband_schluessel", "gemeinde_name", "gemeinde_schluessel"])
4 gemeinden.head()
NameError: name 'pd' is not defined
Wenn wir die Tabellen vergleichen, so stellen wir fest, dass alle eine etwas andere Struktur haben und meist nur einen Teil der Informationen erhalten. Wollen wir zum Beispiel wissen was die Bevölkerungsdichte in den Stadtbezirken mit Baustellen ist, so lässen sich dieses Wissen nicht sofort ableiten.
Tabellen in SQLite speichern mit Pandas#
Um diese Daten langfristig zu speichern wollen wir uns eine Datenbank anlegen. Da die Daten ja bereits als Tabellen vorliegen, nutzen wir eine relationale Datenbank. Eine sehr einfache, lokale relationale Datenbank, die ohne Server auskommt ist SQLite. Sie ist bereits in Python enthalten. Wir erzeugen uns eine neue Datenbank indem wir eine Verbindung zu einer neuen Datenbankdatei anlegen.
import sqlite3
# Create a SQL connection to our SQLite database
con = sqlite3.connect("opendatahro.sqlite")
Wir schauen uns später an wie wir Tabellen direkt mit SQL erzeugen. Pandas hat diese Funktion bereits eingebaut, so dass wir unsere Tabelle direkt in der SQLite Datenbank speichern können.
baustellen.to_sql("baustellen", con, if_exists="replace")
adressenliste.to_sql("adressenliste", con, if_exists="replace")
gemeinden.to_sql("gemeinden", con, if_exists="replace")
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[6], line 1
----> 1 baustellen.to_sql("baustellen", con, if_exists="replace")
2 adressenliste.to_sql("adressenliste", con, if_exists="replace")
3 gemeinden.to_sql("gemeinden", con, if_exists="replace")
NameError: name 'baustellen' is not defined
Daten aus Tabellen abfragen mit SELECT#
SQL ist die Standartsprache um mit relationalen Datenbanken zu arbeiten. Sie bietet verschiedene Befehle um Tabellen zu definieren, Daten in ihnen zu speichern als auch die Daten abzufragen. Letzteres wird mit dem SELECT Befehl gemacht. SQL orientiert sich dabei etwas an natürlicher Sprache. Man fragt in SQL quasi nach den Daten aus (FROM) einer bestimmten Tabelle . Um zum Beispiel alle Spalten aus einer Tabelle abzufragen nutzen wir den Befehl mit dem Platzhalter * (=alle Spalten).
sql='SELECT * FROM baustellen;'
Um den SQL Befehl an die Datenbank zu senden, erzeugen wir aus unserer Datenbankverbindung con einen neuen Cursor cur. Mit cur.execute(sql) führen wir den SQL Befehl aus und die Datenbank sendet und die Datenbank fängt an uns alle Ergebnisse der Anfrage Zeile für Zeile zurück zu senden. Der Cursor zeigt dabei immer auf die aktuelle Zeile. Damit will man vermeiden alle Daten, welche sehr (sehr) viele Zeilen sein können, auf einmal zu senden und damit ggf. das Netzwerk oder das Programm zu überlasten.
cur = con.cursor()
rows = cur.execute(sql)
for i,row in enumerate(rows):
if i<20:
print(row)
print(f"Rows {i}")
print(f"Type {type(row)}")
(0, 54.0892416777378, 12.1167683384065, '06850', 'sonstige temporäre Beschilderung', '4', None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', None, None)
(1, 54.088801599174, 12.1134178633102, '02660', 'Straßenbau', 'Borwinstr. (01500)', 'Waldemarstr. (09410)', '2024-09-22 22:00:00', '2026-02-13 23:00:00', 'Sicherungsmaßnahmen entlang der Straße, Sicherungsmaßnahmen entlang des Gehwegs, Sperrung des Fußgängerverkehrs im Gehwegbereich, Vollsperrung', 'Neubau Entwässerungsleitachse 2. BA')
(2, 54.1405221310946, 12.0450058692315, '01390', 'sonstige temporäre Beschilderung', '12', None, '2026-01-07 06:00:00', '2026-01-07 17:00:00', None, None)
(3, 54.0844314934986, 12.139302910082, '00970', 'sonstige temporäre Beschilderung', '121', None, '2026-01-24 07:00:00', '2026-01-24 13:00:00', None, None)
(4, 54.0745992056138, 12.1397850179645, '08440', 'Hochbau', '8', '10', '2025-07-14 05:00:00', '2026-05-30 14:00:00', 'Sicherungsmaßnahmen entlang der Straße, Sicherungsmaßnahmen entlang des Gehwegs', 'Neubau')
(5, 54.0866495343382, 12.1216285412765, '01320', 'Gebäudesanierung', '10', None, '2025-06-30 22:00:00', '2026-01-30 23:00:00', 'Sicherungsmaßnahmen entlang der Straße, Sicherungsmaßnahmen entlang des Gehwegs, Sperrung des Fußgängerverkehrs im Gehwegbereich, Verkehrsraumeinschränkungen', 'Gerüststellung Haus Nr. 10')
(6, 54.0825760239651, 12.1277905253317, '04370', 'sonstige temporäre Beschilderung', '20', None, '2026-01-07 11:00:00', '2026-01-07 17:00:00', None, None)
(7, 54.1055192781821, 12.1761533753687, '09270', 'Grünpflege', '3', '6', '2026-01-13 23:00:00', '2026-01-21 23:00:00', 'Sicherungsmaßnahmen entlang der Straße, Verkehrsraumeinschränkungen', 'Baumpflanzungen')
(8, 54.0828133702379, 12.1368442190522, '07540', 'Straßenbau', '2', None, '2026-01-04 23:00:00', '2026-02-06 23:00:00', 'Sicherungsmaßnahmen entlang der Straße, Sicherungsmaßnahmen entlang des Gehwegs, Verkehrsraumeinschränkungen', 'Kellersanierung -Baustelleneinrichtung-')
(9, 54.0896616841849, 12.1020365415448, '04340', 'Gebäudesanierung', '67', None, '2026-01-01 23:00:00', '2026-01-31 23:00:00', None, None)
(10, 54.1152786190598, 12.1042318825784, '13290', 'sonstige temporäre Beschilderung', '58a', None, '2026-01-16 07:00:00', '2026-01-16 17:00:00', None, None)
(11, 54.1353326439904, 12.0837188408431, 'B0105', 'Straßenbau', None, None, '2025-12-31 23:00:00', '2026-12-31 23:00:00', 'Sicherungsmaßnahmen entlang der Straße, Verkehrsraumeinschränkungen', 'Wartungs- und Instandsetzungsarbeiten an Wechselverkehrszeichen (WVZ) - AQ0 und AQ1')
(12, 54.0964406113059, 12.1226029662695, '02780', 'Stromnetz', None, None, '2025-09-29 22:00:00', '2026-05-31 22:00:00', 'Verkehrsraumeinschränkungen', 'Netzausbau')
(13, 54.0734975557463, 12.1355377448644, '02030', 'Hochbau', '45', None, '2025-07-31 05:00:00', '2026-05-30 16:00:00', 'Sicherungsmaßnahmen entlang der Straße', 'Baustellenzufahrt')
(14, 54.0828180747948, 12.1360644378225, '07540', 'sonstige temporäre Beschilderung', '33', None, '2026-01-10 11:00:00', '2026-01-10 19:00:00', None, None)
(15, 54.1051556750968, 12.1425855053781, '01820', 'Grünpflege', 'Schenkendorfweg (08200)', 'Bruchweg (14350)', '2026-01-07 08:00:00', '2026-01-09 14:00:00', 'halbseitige Sperrung, Sicherungsmaßnahmen entlang der Straße', 'Grünpflege')
(16, 54.0859221538865, 12.1040614434985, '08830', 'Kranarbeiten', '15', None, '2026-02-05 07:00:00', '2026-02-05 11:00:00', 'Sicherungsmaßnahmen entlang der Straße, Sicherungsmaßnahmen entlang des Gehwegs, Sperrung des Fußgängerverkehrs im Gehwegbereich, Verkehrsraumeinschränkungen', 'Kranarbeiten')
(17, 54.0898431363841, 12.1018466131296, '04340', 'Gebäudesanierung', '65', None, '2026-01-07 23:00:00', '2026-01-08 23:00:00', None, None)
(18, 54.0705146433709, 12.1188940298953, '09920', 'Straßenbau', 'Kurt-Tucholsky-Str. (06380)', 'Majakowskistr. (06830)', '2024-09-22 22:00:00', '2026-04-30 22:00:00', 'Sicherungsmaßnahmen entlang der Straße, Sicherungsmaßnahmen entlang des Gehwegs', 'Grundhafte Erneuerung 2. BA')
(19, 54.0920317902191, 12.1182481424286, '04500', 'Gebäudesanierung', '8', None, '2026-01-07 23:00:00', '2026-01-08 23:00:00', None, None)
Rows 143
Type <class 'tuple'>
Wie wir sehen erhalten wir jede Zeile als Tuple zurück. Dabei kennen wir in diesem Fall nicht die Spaltennamen der Werte. Wir können diese vom Cursor abfragen mit
cur.description
(('index', None, None, None, None, None, None),
('latitude', None, None, None, None, None, None),
('longitude', None, None, None, None, None, None),
('strasse_schluessel', None, None, None, None, None, None),
('sparte', None, None, None, None, None, None),
('von', None, None, None, None, None, None),
('nach', None, None, None, None, None, None),
('baubeginn', None, None, None, None, None, None),
('bauende', None, None, None, None, None, None),
('verkehrsbeeintraechtigungen', None, None, None, None, None, None),
('baumassnahme', None, None, None, None, None, None))
Meist fragt man allerdings nicht alle Spalten einer Tabelle mit dem Platzhalter * ab, sonder gibt geziehlt die Spalten an, die man erhalten möchte. So kann man unnötigen Datenverkehr spaaren.
sql='SELECT sparte, latitude, longitude, baumassnahme FROM baustellen;'
rows = cur.execute(sql)
for i,row in enumerate(rows):
if i<20:
print(row)
print(f"Rows {i}")
('sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None)
('Straßenbau', 54.088801599174, 12.1134178633102, 'Neubau Entwässerungsleitachse 2. BA')
('sonstige temporäre Beschilderung', 54.1405221310946, 12.0450058692315, None)
('sonstige temporäre Beschilderung', 54.0844314934986, 12.139302910082, None)
('Hochbau', 54.0745992056138, 12.1397850179645, 'Neubau')
('Gebäudesanierung', 54.0866495343382, 12.1216285412765, 'Gerüststellung Haus Nr. 10')
('sonstige temporäre Beschilderung', 54.0825760239651, 12.1277905253317, None)
('Grünpflege', 54.1055192781821, 12.1761533753687, 'Baumpflanzungen')
('Straßenbau', 54.0828133702379, 12.1368442190522, 'Kellersanierung -Baustelleneinrichtung-')
('Gebäudesanierung', 54.0896616841849, 12.1020365415448, None)
('sonstige temporäre Beschilderung', 54.1152786190598, 12.1042318825784, None)
('Straßenbau', 54.1353326439904, 12.0837188408431, 'Wartungs- und Instandsetzungsarbeiten an Wechselverkehrszeichen (WVZ) - AQ0 und AQ1')
('Stromnetz', 54.0964406113059, 12.1226029662695, 'Netzausbau')
('Hochbau', 54.0734975557463, 12.1355377448644, 'Baustellenzufahrt')
('sonstige temporäre Beschilderung', 54.0828180747948, 12.1360644378225, None)
('Grünpflege', 54.1051556750968, 12.1425855053781, 'Grünpflege')
('Kranarbeiten', 54.0859221538865, 12.1040614434985, 'Kranarbeiten')
('Gebäudesanierung', 54.0898431363841, 12.1018466131296, None)
('Straßenbau', 54.0705146433709, 12.1188940298953, 'Grundhafte Erneuerung 2. BA')
('Gebäudesanierung', 54.0920317902191, 12.1182481424286, None)
Rows 143
Filtern von Ergebnissen mit WHERE#
Oft will man nur bestimmte Zeilen aus einer Tabelle in einer Datenbank abrufen. Diese Auswahl definiert man mit dem SQL Befehl WHERE und zusätzlichen logischen Vergleichsoperatoren.
Wollen wir zum Beispiel nur die Baustellen haben die einen Baubegin in 2023 haben, so können wir definieren
sql='''SELECT strasse_schluessel, sparte, latitude, longitude, baumassnahme, baubeginn, bauende
FROM baustellen
WHERE baubeginn >= '2023-01-01 00:00:00+01';'''
rows = cur.execute(sql)
for i,row in enumerate(rows):
if i<20:
print(row)
print(f"Rows {i}")
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00')
('02660', 'Straßenbau', 54.088801599174, 12.1134178633102, 'Neubau Entwässerungsleitachse 2. BA', '2024-09-22 22:00:00', '2026-02-13 23:00:00')
('01390', 'sonstige temporäre Beschilderung', 54.1405221310946, 12.0450058692315, None, '2026-01-07 06:00:00', '2026-01-07 17:00:00')
('00970', 'sonstige temporäre Beschilderung', 54.0844314934986, 12.139302910082, None, '2026-01-24 07:00:00', '2026-01-24 13:00:00')
('08440', 'Hochbau', 54.0745992056138, 12.1397850179645, 'Neubau', '2025-07-14 05:00:00', '2026-05-30 14:00:00')
('01320', 'Gebäudesanierung', 54.0866495343382, 12.1216285412765, 'Gerüststellung Haus Nr. 10', '2025-06-30 22:00:00', '2026-01-30 23:00:00')
('04370', 'sonstige temporäre Beschilderung', 54.0825760239651, 12.1277905253317, None, '2026-01-07 11:00:00', '2026-01-07 17:00:00')
('09270', 'Grünpflege', 54.1055192781821, 12.1761533753687, 'Baumpflanzungen', '2026-01-13 23:00:00', '2026-01-21 23:00:00')
('07540', 'Straßenbau', 54.0828133702379, 12.1368442190522, 'Kellersanierung -Baustelleneinrichtung-', '2026-01-04 23:00:00', '2026-02-06 23:00:00')
('04340', 'Gebäudesanierung', 54.0896616841849, 12.1020365415448, None, '2026-01-01 23:00:00', '2026-01-31 23:00:00')
('13290', 'sonstige temporäre Beschilderung', 54.1152786190598, 12.1042318825784, None, '2026-01-16 07:00:00', '2026-01-16 17:00:00')
('B0105', 'Straßenbau', 54.1353326439904, 12.0837188408431, 'Wartungs- und Instandsetzungsarbeiten an Wechselverkehrszeichen (WVZ) - AQ0 und AQ1', '2025-12-31 23:00:00', '2026-12-31 23:00:00')
('02780', 'Stromnetz', 54.0964406113059, 12.1226029662695, 'Netzausbau', '2025-09-29 22:00:00', '2026-05-31 22:00:00')
('02030', 'Hochbau', 54.0734975557463, 12.1355377448644, 'Baustellenzufahrt', '2025-07-31 05:00:00', '2026-05-30 16:00:00')
('07540', 'sonstige temporäre Beschilderung', 54.0828180747948, 12.1360644378225, None, '2026-01-10 11:00:00', '2026-01-10 19:00:00')
('01820', 'Grünpflege', 54.1051556750968, 12.1425855053781, 'Grünpflege', '2026-01-07 08:00:00', '2026-01-09 14:00:00')
('08830', 'Kranarbeiten', 54.0859221538865, 12.1040614434985, 'Kranarbeiten', '2026-02-05 07:00:00', '2026-02-05 11:00:00')
('04340', 'Gebäudesanierung', 54.0898431363841, 12.1018466131296, None, '2026-01-07 23:00:00', '2026-01-08 23:00:00')
('09920', 'Straßenbau', 54.0705146433709, 12.1188940298953, 'Grundhafte Erneuerung 2. BA', '2024-09-22 22:00:00', '2026-04-30 22:00:00')
('04500', 'Gebäudesanierung', 54.0920317902191, 12.1182481424286, None, '2026-01-07 23:00:00', '2026-01-08 23:00:00')
Rows 143
Mehrere Bedingungen können durch logische Operatoren wie ‘AND’, ‘OR’ oder ‘NOT’ verknüpft werden. Wollen wir alle Baustellen die im 1 Quartal 2023 angefangen und beendet werden, so schreiben wir
sql='''SELECT strasse_schluessel, sparte, latitude, longitude, baumassnahme, baubeginn, bauende
FROM baustellen
WHERE baubeginn >= '2025-01-01 00:00:00+01' AND bauende < '2027-01-01 00:00:00+01';'''
rows = cur.execute(sql)
for i,row in enumerate(rows):
if i<20:
print(row)
print(f"Rows {i}")
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00')
('01390', 'sonstige temporäre Beschilderung', 54.1405221310946, 12.0450058692315, None, '2026-01-07 06:00:00', '2026-01-07 17:00:00')
('00970', 'sonstige temporäre Beschilderung', 54.0844314934986, 12.139302910082, None, '2026-01-24 07:00:00', '2026-01-24 13:00:00')
('08440', 'Hochbau', 54.0745992056138, 12.1397850179645, 'Neubau', '2025-07-14 05:00:00', '2026-05-30 14:00:00')
('01320', 'Gebäudesanierung', 54.0866495343382, 12.1216285412765, 'Gerüststellung Haus Nr. 10', '2025-06-30 22:00:00', '2026-01-30 23:00:00')
('04370', 'sonstige temporäre Beschilderung', 54.0825760239651, 12.1277905253317, None, '2026-01-07 11:00:00', '2026-01-07 17:00:00')
('09270', 'Grünpflege', 54.1055192781821, 12.1761533753687, 'Baumpflanzungen', '2026-01-13 23:00:00', '2026-01-21 23:00:00')
('07540', 'Straßenbau', 54.0828133702379, 12.1368442190522, 'Kellersanierung -Baustelleneinrichtung-', '2026-01-04 23:00:00', '2026-02-06 23:00:00')
('04340', 'Gebäudesanierung', 54.0896616841849, 12.1020365415448, None, '2026-01-01 23:00:00', '2026-01-31 23:00:00')
('13290', 'sonstige temporäre Beschilderung', 54.1152786190598, 12.1042318825784, None, '2026-01-16 07:00:00', '2026-01-16 17:00:00')
('B0105', 'Straßenbau', 54.1353326439904, 12.0837188408431, 'Wartungs- und Instandsetzungsarbeiten an Wechselverkehrszeichen (WVZ) - AQ0 und AQ1', '2025-12-31 23:00:00', '2026-12-31 23:00:00')
('02780', 'Stromnetz', 54.0964406113059, 12.1226029662695, 'Netzausbau', '2025-09-29 22:00:00', '2026-05-31 22:00:00')
('02030', 'Hochbau', 54.0734975557463, 12.1355377448644, 'Baustellenzufahrt', '2025-07-31 05:00:00', '2026-05-30 16:00:00')
('07540', 'sonstige temporäre Beschilderung', 54.0828180747948, 12.1360644378225, None, '2026-01-10 11:00:00', '2026-01-10 19:00:00')
('01820', 'Grünpflege', 54.1051556750968, 12.1425855053781, 'Grünpflege', '2026-01-07 08:00:00', '2026-01-09 14:00:00')
('08830', 'Kranarbeiten', 54.0859221538865, 12.1040614434985, 'Kranarbeiten', '2026-02-05 07:00:00', '2026-02-05 11:00:00')
('04340', 'Gebäudesanierung', 54.0898431363841, 12.1018466131296, None, '2026-01-07 23:00:00', '2026-01-08 23:00:00')
('04500', 'Gebäudesanierung', 54.0920317902191, 12.1182481424286, None, '2026-01-07 23:00:00', '2026-01-08 23:00:00')
('06850', 'Gebäudesanierung', 54.0884957878063, 12.1160946296076, 'Mariallagerung, Liftstellung', '2025-12-11 23:00:00', '2026-01-30 23:00:00')
('00190', 'Wasserleitung', 54.1266674220357, 12.0617796779677, 'Trinkwasserrohrbruch - Havariemaßnahme-', '2025-12-22 23:00:00', '2026-01-09 23:00:00')
Rows 125
Daten Aggregieren#
Da die Ergebnisse Zeile für Zeile übertragen werden, ist die Anzahl der Ergebnisse auch nicht unbedingt vorher bekannt. Deshalb unterstützen alle relationale Datenbanken die Aggregatfunktion count(*), um die Anzahl der Zeilen der Ergebnisse zurück zu geben.
sql='SELECT count(*) FROM baustellen;'
for row in cur.execute(sql):
print(row)
(144,)
Hier erhalten wir nur eine Ergebniszeile zurück, mit der Anzahl der Zeilen in der Tabelle.
Darüber hinaus unerstützt SQL viele Aggregierfunktionen. Wollen wir zum Beispiel in unserem Beispieldatensatz die minimalen Baubeginn aller Baustellen identifizieren nutzen wir die min()-Funktion mit dem entsprechenden Spaltennamen.
sql='SELECT min(baubeginn) FROM baustellen;'
for row in cur.execute(sql):
print(row)
('2023-02-19 23:00:00',)
Wieder erhalten wir ein Ergebnis mit dem Datum. Das entscheidende ist, dass diese Aggregatfunktionen direkt in der Datenbank ausgeführt wird. Wir müssen also nicht alle Daten runterladen, um einfache Kennwerte wie die Anzahl, das Minimum oder Maximum von Spalten zu erhalten. Dabei können wir auch mehrere Aggregierungen in einer Anfrage und mathematische Berechnungen ausführen. Das folgende Beispiel gibt uns die Anzahl der Baustellen sowie den minimalen Baubeginn und das maximale Bauende sowie die Baudauer. Die Baudauer berechnen wir direkt in der Datenbank als den arithmethischen Durchschnitt avg der Differenz zwischen Bauende und Baubeginn in Tagen im Julianischen Kalender.
sql='''SELECT count(*), min(baubeginn), max(bauende), avg(JulianDay(bauende)-JulianDay(baubeginn))
FROM baustellen;'''
for row in cur.execute(sql):
print(row)
(144, '2023-02-19 23:00:00', '2027-12-31 23:00:00', 215.47120949074613)
Statistiken Extrahieren mit Aggregieren von Gruppen, Sortieren und Limitieren#
Das letzte Beispiel zeigt bereits, wie wir SQL nutzen können um Statistiken der Daten in einer Datenbank zu berechnen. Das wird besonders dann interessant, wenn wir das mit Gruppierungen kombinieren. Gruppierungen fassen die abgefragten Zeilen in der Tabelle entlang den angegebenen Spaltennamen als Gruppe zusammen. Wollen wir zum Beispiel wissen, wie lange im Durchschnitt die Dauer der Baustellen je nach sparte ist, so können wir diese Spalte als Gruppe definieren und die mittleren Baudauer für jede Gruppe bestimmen. Dafür bietet SQL den Befehl GROUP BY an, hinter dem wir die Spalte angeben nach welcher gruppiert werden soll.
sql='''SELECT sparte, count(*), min(baubeginn), max(bauende), AVG(julianday(bauende) - julianday(baubeginn))
FROM baustellen
GROUP BY sparte;'''
for row in cur.execute(sql):
print(row)
('Abwasserleitung', 1, '2025-11-23 23:00:00', '2026-12-31 23:00:00', 403.0)
('Baumfällarbeiten', 1, '2026-01-05 07:00:00', '2026-01-23 14:00:00', 18.291666666977108)
('Brückensanierung', 1, '2025-03-24 07:00:00', '2026-04-24 14:00:00', 396.2916666669771)
('Fernwärmeleitung', 8, '2025-09-01 05:00:00', '2026-06-27 22:00:00', 145.33333333331393)
('Gasleitung', 2, '2025-09-22 05:00:00', '2026-03-31 16:00:00', 153.45833333325572)
('Gebäudesanierung', 32, '2024-09-10 22:00:00', '2027-07-30 22:00:00', 178.94140624998545)
('Grünpflege', 9, '2025-08-11 22:00:00', '2026-08-31 22:00:00', 102.15277777772604)
('Hochbau', 23, '2023-02-19 23:00:00', '2027-12-31 23:00:00', 567.0235507245905)
('Kabelnetz', 10, '2026-01-04 23:00:00', '2026-02-06 23:00:00', 11.8)
('Kranarbeiten', 2, '2025-12-15 23:00:00', '2026-02-05 11:00:00', 16.083333333488554)
('Straßenbau', 17, '2023-05-01 22:00:00', '2027-12-31 23:00:00', 390.2696078431738)
('Stromnetz', 9, '2025-06-22 22:00:00', '2026-10-18 22:00:00', 116.82407407416031)
('Telefonnetz', 3, '2026-01-05 07:00:00', '2026-01-16 23:00:00', 2.5833333333333335)
('Wasserleitung', 4, '2025-05-25 22:00:00', '2026-05-29 22:00:00', 107.61458333337214)
('privat', 3, '2025-07-13 22:00:00', '2026-05-29 22:00:00', 255.6527777776743)
('sonstige temporäre Beschilderung', 19, '2026-01-06 05:30:00', '2026-02-14 17:00:00', 0.6480263158384907)
Wir sehen jetzt, dass ‘Hochbau’ die größte Gruppen mit 29 Zeilen (Baustellen) bildet, gefolgt von Straßenbau mit 14 Zeilen. Hochbau braucht Hochbau mit 507 Tagen fast doppelt so lange wie Strassenbau mit 274 Tagen.
(Da wir die Daten tagesaktuell von Opendata-HRO laden, können sich diese Beispielzahlen im Verlauf der Zeit durchaus ändern).
Um die Ergebnisse zu sortieren bietet SQL den ORDER BY Befehl. Wollen wir die Ergebnisse nach der Dauer absteigend (DESC) sortieren, so schreiben wir:
sql='''SELECT sparte, count(*), min(baubeginn), max(bauende), JulianDay(avg(bauende))-JulianDay(avg(baubeginn)) as Baudauer
FROM baustellen
GROUP BY sparte
ORDER BY Baudauer DESC;''' # ASC - Aufsteigend, DESC - Absteigend
for row in cur.execute(sql):
print(row)
('Hochbau', 23, '2023-02-19 23:00:00', '2027-12-31 23:00:00', 1.5652173842590855)
('Straßenbau', 17, '2023-05-01 22:00:00', '2027-12-31 23:00:00', 1.1764705902778587)
('privat', 3, '2025-07-13 22:00:00', '2026-05-29 22:00:00', 1.0)
('Gasleitung', 2, '2025-09-22 05:00:00', '2026-03-31 16:00:00', 1.0)
('Brückensanierung', 1, '2025-03-24 07:00:00', '2026-04-24 14:00:00', 1.0)
('Abwasserleitung', 1, '2025-11-23 23:00:00', '2026-12-31 23:00:00', 1.0)
('Fernwärmeleitung', 8, '2025-09-01 05:00:00', '2026-06-27 22:00:00', 0.875)
('Gebäudesanierung', 32, '2024-09-10 22:00:00', '2027-07-30 22:00:00', 0.8125)
('Wasserleitung', 4, '2025-05-25 22:00:00', '2026-05-29 22:00:00', 0.75)
('Stromnetz', 9, '2025-06-22 22:00:00', '2026-10-18 22:00:00', 0.6666666666667425)
('Grünpflege', 9, '2025-08-11 22:00:00', '2026-08-31 22:00:00', 0.5555555555556566)
('Kranarbeiten', 2, '2025-12-15 23:00:00', '2026-02-05 11:00:00', 0.5)
('sonstige temporäre Beschilderung', 19, '2026-01-06 05:30:00', '2026-02-14 17:00:00', 0.0)
('Telefonnetz', 3, '2026-01-05 07:00:00', '2026-01-16 23:00:00', 0.0)
('Kabelnetz', 10, '2026-01-04 23:00:00', '2026-02-06 23:00:00', 0.0)
('Baumfällarbeiten', 1, '2026-01-05 07:00:00', '2026-01-23 14:00:00', 0.0)
Sind wir jetzt nur an der Top 3 interessiert, so können wir mit LIMIT die Anzahl an Ergebnissen die maximal zurück gegeben werden.
sql='''SELECT sparte, count(*) as CNT, min(baubeginn), max(bauende), JulianDay(avg(bauende))-JulianDay(avg(baubeginn)) as Baudauer
FROM baustellen
GROUP BY sparte
ORDER BY Baudauer DESC
LIMIT 3;'''
for row in cur.execute(sql):
print(row)
('Hochbau', 23, '2023-02-19 23:00:00', '2027-12-31 23:00:00', 1.5652173842590855)
('Straßenbau', 17, '2023-05-01 22:00:00', '2027-12-31 23:00:00', 1.1764705902778587)
('privat', 3, '2025-07-13 22:00:00', '2026-05-29 22:00:00', 1.0)
Daten aus mehreren Tabellen verknüpfen und gleichzeitig abfragen mit JOIN#
In unserm Beispiel kennen wir nicht die Straßennamen der Baustelle, sondern nur eine obskure ID namens strasse_schluessel. Diese finden wir auch in der Tabelle adressenliste zusammen mit dem gesuchten Straßennamen. Wir müssen also nun eine Abfrage über beide Tabellen gemeinsam durchführen, um auch die Straße für die Baustellen zu erfahren. Dafür nutzt man den SQL Befehl JOIN und gibt an wo (WHERE) die Ergebnisse zusammenzuführen sind indem man eine Gleichheitsbedingung spezifiziert. Da die Spalte strasse_schluessel in beiden Tabellen vorkommt und es nicht ganz eindeutig ist auf welche man sich bezieht, gibt man jetzt auch bei den Spaltennamen die Tabelle mit der Dotnotation mit an, also:
sql='''SELECT baustellen.strasse_schluessel, baustellen.sparte, baustellen.latitude, baustellen.longitude, baustellen.baumassnahme, baustellen.baubeginn, baustellen.bauende,
adressenliste.gemeindeteil_name, adressenliste.strasse_name
FROM baustellen
JOIN adressenliste
WHERE baustellen.strasse_schluessel=adressenliste.strasse_schluessel LIMIT 10;'''
for row in cur.execute(sql):
print(row)
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
Da diese ständige Wiederholung der Tabellennamen sehr schreiblastig ist, kann man in SQL mit dem Befehl AS auch kürzere Namen für Spalten und Tabellen verwenden
sql='''SELECT b.strasse_schluessel, b.sparte, b.latitude, b.longitude, b.baumassnahme, b.baubeginn, b.bauende,
a.gemeindeteil_name, a.strasse_name
FROM baustellen AS b
JOIN adressenliste AS a
WHERE b.strasse_schluessel=a.strasse_schluessel LIMIT 10;'''
for row in cur.execute(sql):
print(row)
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, '2026-01-07 05:00:00', '2026-01-09 15:00:00', 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
Jetzt kommt es allerdings zu vielen Dopplungen in unseren Ergebnissen, da jede Ergebniszeile aus der Tabelle baustellen mit jeder Zeile aus der Tabelle adressenliste wiederholt wird, weil in der letzteren ja eine Straße mit dem gleichen strasse_schluessel mehrmals vorkommt. Diese Duplikate wollen wir rausfiltern mit dem SQL Befehl DISTINCT
sql='''SELECT DISTINCT b.strasse_schluessel, b.sparte, b.latitude, b.longitude, b.baumassnahme, a.gemeindeteil_name, a.strasse_name
FROM baustellen AS b
JOIN adressenliste AS a
WHERE b.strasse_schluessel=a.strasse_schluessel LIMIT 10;'''
for row in cur.execute(sql):
print(row)
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.')
('02660', 'Straßenbau', 54.088801599174, 12.1134178633102, 'Neubau Entwässerungsleitachse 2. BA', 'Kröpeliner-Tor-Vorstadt', 'Fritz-Reuter-Str.')
('01390', 'sonstige temporäre Beschilderung', 54.1405221310946, 12.0450058692315, None, 'Lütten Klein', 'Binzer Str.')
('00970', 'sonstige temporäre Beschilderung', 54.0844314934986, 12.139302910082, None, 'Stadtmitte', 'Augustenstr.')
('08440', 'Hochbau', 54.0745992056138, 12.1397850179645, 'Neubau', 'Stadtmitte', 'Schwaaner Landstr.')
('08440', 'Hochbau', 54.0745992056138, 12.1397850179645, 'Neubau', 'Südstadt', 'Schwaaner Landstr.')
('01320', 'Gebäudesanierung', 54.0866495343382, 12.1216285412765, 'Gerüststellung Haus Nr. 10', 'Kröpeliner-Tor-Vorstadt', 'Bergstr.')
('04370', 'sonstige temporäre Beschilderung', 54.0825760239651, 12.1277905253317, None, 'Stadtmitte', 'Karlstr.')
('09270', 'Grünpflege', 54.1055192781821, 12.1761533753687, 'Baumpflanzungen', 'Dierkow-Neu', 'Theodor-Heuss-Str.')
('07540', 'Straßenbau', 54.0828133702379, 12.1368442190522, 'Kellersanierung -Baustelleneinrichtung-', 'Stadtmitte', 'Paulstr.')
Jetzt kennen wir schon den richtigen Straßenname zu jeder Baustelle, allerdings fehlt uns die Gemeinde. Hierfür verknüpfen wir die Daten mit der Tabelle
gemeinden. Dafür ergänzen wir die zusätzliche Tabelle im JOIN und definieren die weitere Verknüpfungsbedingung auf die Spalte gemeinde_schluessel.
sql='''SELECT DISTINCT b.strasse_schluessel, b.sparte, b.latitude, b.longitude, b.baumassnahme, a.gemeindeteil_name, a.strasse_name, g.gemeinde_name
FROM baustellen AS b
JOIN adressenliste AS a, gemeinden AS g
WHERE b.strasse_schluessel=a.strasse_schluessel AND a.gemeinde_schluessel=g.gemeinde_schluessel LIMIT 10;'''
for row in cur.execute(sql):
print(row)
('06850', 'sonstige temporäre Beschilderung', 54.0892416777378, 12.1167683384065, None, 'Kröpeliner-Tor-Vorstadt', 'Margaretenstr.', 'Rostock, Hanse- und Universitätsstadt')
('02660', 'Straßenbau', 54.088801599174, 12.1134178633102, 'Neubau Entwässerungsleitachse 2. BA', 'Kröpeliner-Tor-Vorstadt', 'Fritz-Reuter-Str.', 'Rostock, Hanse- und Universitätsstadt')
('01390', 'sonstige temporäre Beschilderung', 54.1405221310946, 12.0450058692315, None, 'Lütten Klein', 'Binzer Str.', 'Rostock, Hanse- und Universitätsstadt')
('00970', 'sonstige temporäre Beschilderung', 54.0844314934986, 12.139302910082, None, 'Stadtmitte', 'Augustenstr.', 'Rostock, Hanse- und Universitätsstadt')
('08440', 'Hochbau', 54.0745992056138, 12.1397850179645, 'Neubau', 'Stadtmitte', 'Schwaaner Landstr.', 'Rostock, Hanse- und Universitätsstadt')
('08440', 'Hochbau', 54.0745992056138, 12.1397850179645, 'Neubau', 'Südstadt', 'Schwaaner Landstr.', 'Rostock, Hanse- und Universitätsstadt')
('01320', 'Gebäudesanierung', 54.0866495343382, 12.1216285412765, 'Gerüststellung Haus Nr. 10', 'Kröpeliner-Tor-Vorstadt', 'Bergstr.', 'Rostock, Hanse- und Universitätsstadt')
('04370', 'sonstige temporäre Beschilderung', 54.0825760239651, 12.1277905253317, None, 'Stadtmitte', 'Karlstr.', 'Rostock, Hanse- und Universitätsstadt')
('09270', 'Grünpflege', 54.1055192781821, 12.1761533753687, 'Baumpflanzungen', 'Dierkow-Neu', 'Theodor-Heuss-Str.', 'Rostock, Hanse- und Universitätsstadt')
('07540', 'Straßenbau', 54.0828133702379, 12.1368442190522, 'Kellersanierung -Baustelleneinrichtung-', 'Stadtmitte', 'Paulstr.', 'Rostock, Hanse- und Universitätsstadt')
Es gibt verschiedene Typen von Joins je nachdem ob man nur die Ergebnisse haben will für die es:
Einträge in beiden Tabellen gibt (INNER, Default)
Einträge in mindestens der ersten Tabelle gibt (RIGHT)
Einträge in mindestens der zweiten Tabelle gibt (LEFT)
Einträge in mindestens der zweiten Tabelle gibt (OUTER)
Der NATURAL JOIN Typen vereinfachen die Schreibarbeit. Beim NATURAL JOIN werden dabei die Spalten gematcht, welche identisch heißen. Er funktioniert somit nur wenn die Spalten in den zu matchenden Tabellen identisch heißen und alle anderen Spalten andere Namen haben, was eher seltener der Fall ist.
sqlNJ='''SELECT DISTINCT strasse_schluessel, sparte, latitude, longitude, baumassnahme, gemeindeteil_name, strasse_name, gemeinde_name
FROM baustellen
NATURAL JOIN adressenliste, gemeinden;'''
for row in cur.execute(sqlNJ):
print(row)
Warning
Es funktioniert auch in diesem Beispiel nicht. Es werden zwar Ergebnisse zurück gegeben, allerdings, deutlich mehr als im letzten Join. Die Gemeinden werden hier kreuzkombiniert. Man sieht also, dass der NATURAL JOIN mit Vorsicht zu benutzen ist.
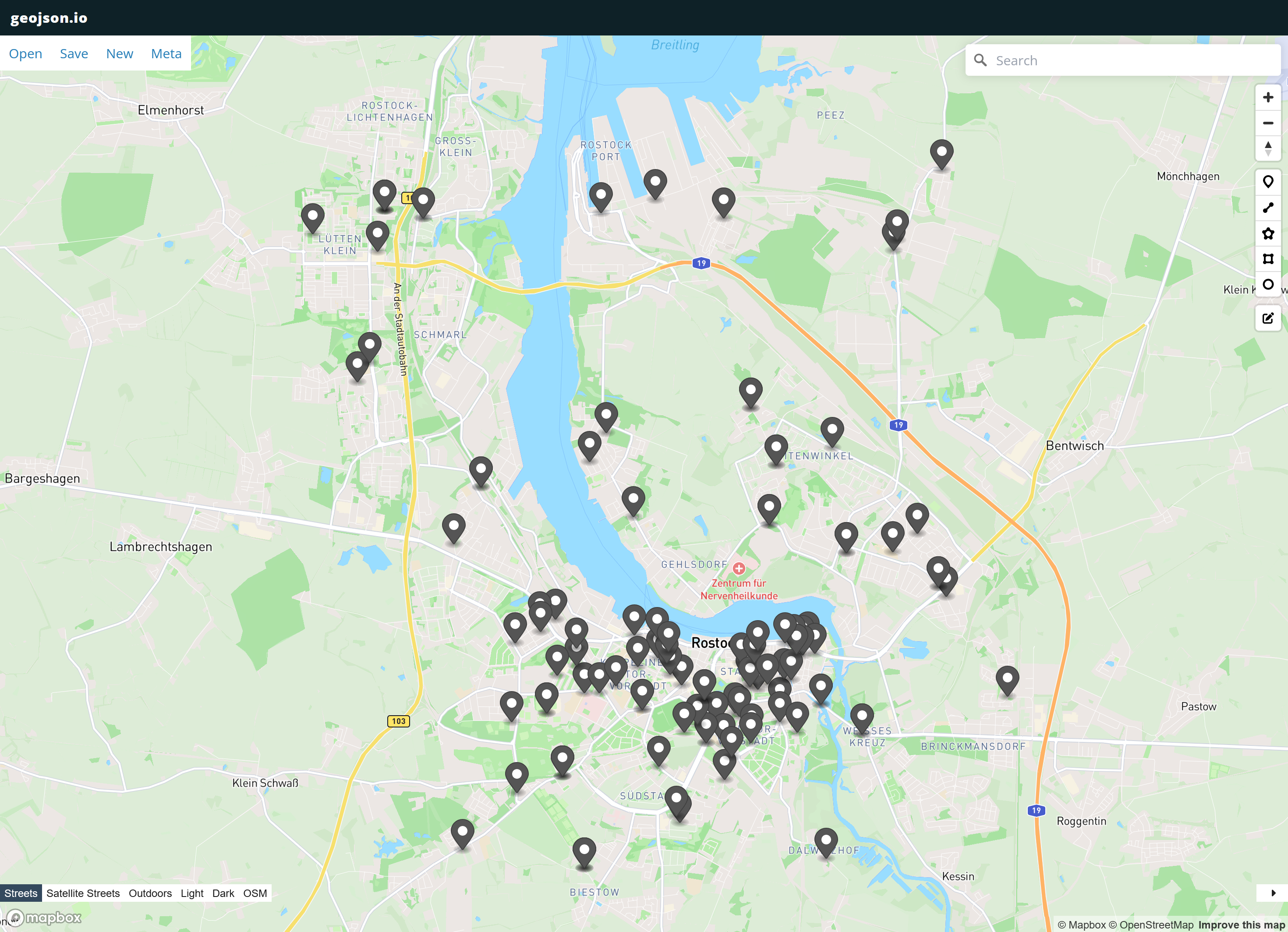
Daten mit SQL und Pandas abfragen und mit GeoJSON visualisieren#
Wir haben am Anfang ja die Tabellen in der SQLite Datenbank bereits mit Pandas erzeugt. Wir können Pandas auch nutzen um Daten aus einer SQL Anfrage direkt als Dataframe (Pandas Tabelle) zu laden.
Fügen wir einmal die Beispiele zusammen und lassen uns alle Baustellen mit Strasse und Gemeinde im ersten Quartal 2023 auf einer Karte anzeigen. Die SQL Abfrage dazu sieht wie folgt aus
sql='''SELECT DISTINCT b.strasse_schluessel, b.sparte, b.latitude, b.longitude, b.baumassnahme, b.baubeginn, b.bauende, a.gemeindeteil_name, a.strasse_name, g.gemeinde_name
FROM baustellen AS b
JOIN adressenliste AS a, gemeinden AS g
WHERE b.strasse_schluessel=a.strasse_schluessel AND a.gemeinde_schluessel=g.gemeinde_schluessel
AND b.baubeginn >= '2023-01-01 00:00:00+01' ;'''
Wir führen die SQL Abfrage direkt mit der Pandas Funktion pd.read_sql(sql, con) aus und erzeugen uns einen DataFrame der die gewünschten Daten enthält.
baustellen_mit_strasse = pd.read_sql(sql, con)
baustellen_mit_strasse
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[25], line 1
----> 1 baustellen_mit_strasse = pd.read_sql(sql, con)
2 baustellen_mit_strasse
NameError: name 'pd' is not defined
Die Tabelle enthält ja bereits die Latitude und Longitude. Mit dem Paket pandas_geojson können wir aus den Dataframe in ein GeoJSON FeatureCollection umwandeln. Wir installieren zuerst das Paket mit pip.
import json
def to_geojson(df, lat, lon, properties=None):
features = []
for _, row in df.iterrows():
features.append({
"type": "Feature",
"geometry": {
"type": "Point",
"coordinates": [row[lon], row[lat]]
},
"properties": {k: row[k] for k in properties or []}
})
return json.dumps({
"type": "FeatureCollection",
"features": features
})
geo_json = to_geojson(df=baustellen_mit_strasse, lat='latitude', lon='longitude',
properties=['strasse_name','sparte','baumassnahme', 'baubeginn', 'bauende'])
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[27], line 19
6 features.append({
7 "type": "Feature",
8 "geometry": {
(...) 12 "properties": {k: row[k] for k in properties or []}
13 })
14 return json.dumps({
15 "type": "FeatureCollection",
16 "features": features
17 })
---> 19 geo_json = to_geojson(df=baustellen_mit_strasse, lat='latitude', lon='longitude',
20 properties=['strasse_name','sparte','baumassnahme', 'baubeginn', 'bauende'])
NameError: name 'baustellen_mit_strasse' is not defined
Jetzt können wir uns die Baustellen mit dem schon bekannten Paket geojsonio auf einer Karte visualisieren.
import json
import geojsonio
geojsonio.display(json.dumps(geo_json))